
Apprentissage profond et GPU, le mariage parfait
Véhicules autonomes, ordinateurs capables de battre des champions de Go, à moins de vivre complètement coupé du monde, il est difficile de passer à côté des prouesses des algorithmes d’apprentissage machine. En effet, ces dernières années les exploits des réseaux de neurones profonds ont largement dépassé le cadre des publications scientifiques pour envahir les gros titres des médias grands publics. Plus proches de nous, l’intelligence artificielle a envahi notre quotidien particulièrement au travers de nos smartphones. Les réseaux de neurones nous permettent ainsi de les déverrouiller rien qu’en les regardant, de sublimer les photos au delà des capacités de leurs capteur tout en identifiant les personnes qui apparaissent dessus, ou encore de répondre à nos requêtes vocales.
Pourtant, si la médiatisation des réseaux de neurones est récente, les fondements théoriques derrière ces algorithmes sont beaucoup plus anciens et remontent aux années 40 avant d’être développés à nouveau dans les années 80. Il faudra cependant attendre le milieu des années 2000 pour connaître le véritable essor des réseaux de neurones. Les raisons sont simples : pour être efficaces ces algorithmes nécessitent des quantités de données phénoménales, que l’avènement d’internet a facilité. Et surtout, il a fallut attendre que les capacités des ordinateurs soient suffisantes pour traiter toutes ces données.
En effet, l’explosion des performances des processeurs à la fin des années 90 et la rapide augmentation de la capacité mémoire des ordinateurs a permis de complexifier les réseaux de neurones afin des les rendre capables d’accomplir de véritables exploits qui semblaient hors de portée des approches traditionnelles. Et c’est l’apparition, au début des années 2000, d’un composant que rien ne présageait à un tel impact dans l’informatique moderne, qui va s’imposer comme le parfait support pour de tels algorithmes : le GPU.
Une brève histoire du GPU
Quel est le rapport entre Quake et les réseaux de neurones profonds ? A priori aucun, et pourtant. Avec son moteur 3D impressionnant pour l’époque, Quake a révolutionné le monde du jeu vidéo sur ordinateur en démontrant que les jeux d’action nerveux en 3D polygonale n’étaient pas l’apanage des seules consoles de jeux. Son succès a initié le développement d’un nouveau marché : celui des accélérateurs graphiques. Si les premiers pas sont hésitants, ces précurseurs se révélant plus lents que les moteurs de rendu logiciels très optimisés, la loi de Moore va leur permettre de rapidement progresser et d’offrir des performances de tout premier plan.

Des débuts modestes
En 1995 une jeune startup fait sensation avec son chipset Voodoo qui impressionne les joueurs en laissant loin derrière les consoles de l’époque. Il faut dire que ce chipset avait été initialement conçu pour les bornes d’arcade. En effet, le business plan initial de 3Dfx prévoyait d’investir en premier lieu le marché des salles d’arcade, le temps de rendre sa technologie plus abordable pour se consacrer au PC. Mais l’effondrement du prix des mémoires va lui permettre d’accélérer ses plans.

Si la 3Dfx s’impose comme une référence, tant par ses performances exceptionnelles, que par sa qualité de rendu elle n’en est pas parfaite pour autant. Malgré la baisse du prix des mémoires, la carte reste chère, d’autant que c’est une carte purement 3D : elle vient s’installer en complément de la carte graphique du PC et ne fonctionne qu’en plein écran, dans les jeux 3D. Une foule de concurrents se presse donc en misant sur d’autres atouts, comme le prix ou la simplicité d’utilisation, le chipset Voodoo restant intouchable d’un point de vue des performances. Parmi eux, on retrouve des grands noms de l’époque, déjà célèbres pour leurs cartes 2D, comme S3, Matrox ou ATI. Mais on trouve aussi des petits nouveaux, au premier rang desquels une jeune startup californienne du nom de NVIDIA.
Pourtant les premiers produits de la marque n’ont rien de remarquable. Le NV1, son premier chip graphique sorti en 1995, sera un échec cuisant qui manquera de peu de couler la toute jeune société comme l’avouera plus tard son PDG, Jen Hsun Huang :

Les raisons de l’échec sont multiples, mais la principale est de ne pas avoir bien su lire l’évolution du marché. Alors que tout le monde se dirige vers une technologie directement inspirée du modèle de SGI qui s’appuie sur les triangles, NVIDIA s’accroche à l’idée de baser sa puce sur une technique appelée “quadratic texture mapping” qui utilise des quadrangles comme primitive de rendu, un peu à l’image de ce que faisait Sega avec sa Saturn à la même époque.

Le parallèle n’est pas anodin car un accord avec Sega permettra le portage de quelques uns des hits de la marque Japonaise sur le NV1. Mais cela sera insuffisant pour changer le destin de cette puce déjà condamnée d’avance. L’avènement de DirectX aura raison de cette technique de rendu et signera la fin du NV1 et de son successeur le NV2, qui ne sera jamais commercialisé. Cet échec ne sera pas pour déplaire à John Carmack qui n’aura pas de mots assez durs pour qualifier cette puce:

Ce premier revers marquera durablement NVIDIA qui, par la suite, suivra à la lettre les standards du marché. Avec l’annulation du NV2, NVIDIA mise l’avenir de la société sur le NV3 et avec un tel enjeu, hors de question de miser sur des excentricités techniques : le NV3 s’appuie méticuleusement sur les spécifications de DirectX 5. Commercialisé à l’été 1997 sous le nom commercial de Riva 128, le NV3 s’avère être extrêmement performant, parvenant même à supplanter la référence de l’époque, la fameuse 3Dfx. Pourtant le NV3 n’est pas parfait, si ses performances sont excellentes, beaucoup de joueurs sont déçus de la qualité d’image proposée et pensent que NVIDIA joue là dessus afin d’obtenir une telle vitesse. Même si NVIDIA corrigera une grande partie des problèmes par la suite, la réputation de cette puce restera entachée par cette controverse initiale. Heureusement, cet incident ne portera pas trop préjudice à la nouvelle puce de NVIDIA, grâce à un excellent rapport qualité prix lui permettant de connaître un joli succès.

Le Riva 128 ne gardera pas longtemps la couronne des performances. Dès le début de l’année 1998, 3DFx sortira un successeur à son chipset Voodoo, le Voodoo2 qui marquera encore les esprits en étant deux fois plus rapide que son prédécesseur. Grisé par le succès de sa dernière puce, NVIDIA ne compte pas s’arrêter là et annonce rapidement un successeur au NV3 : le NV4 ou Riva TNT. Les caractéristiques annoncées par NVIDIA laissent rêveur, mais lorsque la puce arrive finalement à l’été 1998, NVIDIA a été contraint de revoir les fréquences à la baisse : 90MHz au lieu des 110 annoncés. En dépit de cet aléas, le NV4 s’avère être un redoutable concurrent à la Voodoo2. Et cette fois, aucune controverse sur la qualité de rendu ne vient perturber le lancement de cette puce.
Mais NVIDIA n’est pas du genre à s’endormir sur ses lauriers et enchaîne les puces avec une régularité exemplaire. Dès le printemps 1999, le NV5 ou Riva TNT2, débarque. Grace à un nouveau procédé de gravure en 0.25 μm, la dernière puce de NVIDIA dépasse largement les fréquences espérées pour le NV4 et atteint 125MHz et même 150MHz pour la variante Ultra. Certains constructeurs n’hésiteront pas à pousser les fréquences encore plus haut. Cette fois, il n’y a plus aucune contestation possible : la TNT2 Ultra est la carte la plus performante du moment et s’impose comme le chouchou des joueurs.
NVIDIA seul au monde

Après un tel succès, NVIDIA aurait pu se sentir écrasé par la pression mais ce n’est pas le genre de la jeune société. Pour sa nouvelle puce, NVIDIA veut marquer une véritable rupture, traduite par le nom de code NV10, impliquant un changement de génération. Cette volonté se retrouve aussi dans la dénomination commerciale qui abandonne la marque TNT, qui avait pourtant une excellente réputation auprès des joueurs, il faudra désormais s’habituer à GeForce 256 qui arrive à la rentrée 1999. Et ce n’est pas tout, pour bien marquer l’importance prise par les puces 2D/3D, NVIDIA introduit un nouveau terme pour désigner son dernier né : le GPU pour Graphics Processing Unit.

Pourquoi un tel honneur ? Car c’est la première fois qu’une puce grand public intègre tout le pipeline 3D en hardware. En effet, jusqu’ici, les puces 3D se chargeaient essentiellement de la rastérisation et du shading. La rastérisation est le processus permettant de déterminer les pixels couverts par les triangles et le shading détermine la couleur des pixels en combinant le résultat des calculs d’éclairage avec les textures. En revanche, toute la partie géométrique en amont, comme la transformation des sommets, était prise en charge par le CPU. Avec sa GeForce, NVIDIA grâce à DirectX 7, prend en charge le T&L (Transform & Lighting), ces fameux calculs de transformations géométriques et d’éclairage, limitant par là même l’impact du CPU dans les jeux 3D, au grand dam d’intel.


Pourtant, en dépît de son avance technologique, les premiers résultats du NV10 sont loin d’être aussi impressionnant qu’espérés, la faute à une bande passante mémoire qui ne parvient pas à alimenter le GPU suffisamment vite. NVIDIA, bien conscient du problème, proposera rapidement une nouvelle déclinaison de sa puce équipée de mémoire DDR, largement plus rapide et permettant à son nouveau GPU d’atteindre son plein potentiel.

Pendant ce temps, la concurrence tente de suivre désespérément le rythme effréné de la firme au caméléon. 3dfx, le plus redoutable concurrent de NVIDIA, n’est plus que l’ombre de la société qui dominait outrageusement le marché des cartes 3D. Engluée dans le développement de sa nouvelle architecture, la firme doit se reposer sur son système SLI, permettant de coupler plusieurs puces, afin d’obtenir des cartes compétitives mais en termes de fonctionnalités, on se situe plus proche d’une TNT2 que d’une GeForce. Si Matrox a réussi à offrir un concurrent redoutable au couple TNT2/TNT2 Ultra avec sa G400 et G400 Max, la firme canadienne n’a rien en stock pour concurrencer la GeForce. S3 tentera d’offrir la première carte supportant le T&L avec la Savage 2000 mais des drivers catastrophiques et des performances en retrait ne lui permettront pas de revenir sur le devant de la scène.

Seule ATI fait encore illusion en proposant son R100, plus connu sous le nom de Radeon. En termes de fonctionnalités, le GPU de la firme canadienne est compétitif, mais c’est au niveau des drivers et des performances que le bât blesse. Pourtant la Radeon est la seule concurrente crédible des GeForce au tournant de l’an 2000.
Las, alors que la concurrence pointe à peine le bout de son nez, NVIDIA enfonce le clou avec un nouveau GPU : le NV15, intégré à la GeForce 2 GTS qui offre des performances 40% supérieures à la première GeForce. NVIDIA se paiera même le luxe de sortir un nouveau modèle à l’été 2000 : la GeForce 2 Ultra, qui pousse les fréquences GPU/VRAM de 200/166MHz à 250/230MHz. NVIDIA est de nouveau intouchable.
En Février 2001, changement de décor, c’est sur la scène du MacWorld de Tokyo que le NV20, ou GeForce 3, est introduit par nul autre que Steve Jobs en personne. Le volubile patron d’Apple, ne tarit pas d’éloges pour qualifier le NV20, le présentant comme un nouveau jalon dans le monde de l’infographie temps réel. Il faut dire que le nouveau GPU de NVIDIA introduit une nouvelle fonctionnalité majeure : le support des shaders. Les shaders sont des petits programmes permettant de contrôler la façon dont le GPU va générer les images.

Jusqu’ici, les GPU étaient configurables: on parlait de pipeline fixe car on ne pouvait interagir que de façon bien spécifique avec le pipeline graphique. Avec le NV20, le pipeline devient programmable, du moins en partie. Le programmeur peut désormais contrôler la façon dont les sommets son transformés et éclairés, et la façon dont les couleurs sont combinées avec les textures par le biais de ces fameux shaders.
Encore une fois, ATI tente de répondre quelques mois plus tard grâce au R200 ou Radeon 8500, un nouveau GPU dont les fonctionnalités vont plus loin que celles de la GeForce 3. Mais la firme peine encore à concurrencer efficacement les puces de NVIDIA au niveau des performances, la faute à des drivers qui ne sont pas à la hauteur de leur matériel contrairement à ceux de NVIDIA, parfaitement optimisés.
La chute de NVIDIA, le renouveau d’ATI
A l’aube de l’année 2002, tout va pour le mieux pour NVIDIA. La firme Californienne est le leader incontestable du marché des cartes graphiques haut de gamme et vient même d’investir le marché console, grâce à un contrat en or pour fournir le GPU et le chipset de la Xbox, la première console de Microsoft. C’est dans ce contexte que NVIDIA introduit son NV25, une déclinaison du NV20 augmentant le nombre d’unités de vertex shading et la fréquence, pour atteindre une fois encore, des performances de premier plan.

Rien ne laisse présager que les choses pourraient mal tourner, mais comme bien souvent dans ce genre de situations, plus dure sera la chute. le premier avertissement arrive quelques mois plus tard et fait l’effet d’un coup de tonnerre : A l’été 2002, ATI introduit son R300, le premier GPU DirectX 9. La Radeon 9700, puisque tel est son nom commercial, ne se contente pas de griller la politesse à NVIDIA, il enfonce aussi les performances du haut de gamme de la firme la GeForce 4 Ti 4600.
Pour expliquer un tel revirement de situation, il faut revenir quelques années en arrière, ATI achète alors une startup fondés par des anciens de SGI : ArtX, célèbre pour avoir fourni le GPU de la GameCube de Nintendo, le Flipper. C’est cette nouvelle équipe Californienne, qui se charge du R300 dont le développement a commencé en parallèle du R200. Cette stratégie, a permis à ATI de rattraper son retard sur NVIDIA et même de dépasser son concurrent.

Pourtant, beaucoup de joueurs, préfèrent attendre la réponse de la firme de Santa Clara. Il faut dire que NVIDIA commence à communiquer sur sa nouvelle architecture, du nom de NV30 qui s’annonce révolutionnaire. Gravée en 0.13µ, la nouvelle puce est sensée proposer des fonctionnalités qui vont bien au delà de DirectX 9. NVIDIA fait miroiter un GPU dont les possibilités en termes de rendu, seraient capables de rivaliser avec ce que l’on peut voir au cinéma, comme le sous entend le nom de sa technologie CineFX. Mais si NVIDIA enchaîne les présentations grandiloquentes, le GPU lui se fait discret.

Lorsque la puce arrive enfin au début 2003 sous le nom de GeForce FX c’est une énorme déception. Les performances sont à peines équivalentes à celles de la Radeon pourtant disponibles depuis plusieurs mois. Pire encore, pour atteindre ce niveau de performances, NVIDIA a poussé la puce dans ses derniers retranchements, et a été contraint d’utiliser un système de refroidissement surdimmensionné et extrêmement bruyant. Et pourtant, malgré tous les efforts de NVIDIA, les testeurs constatent rapidement que le dernier né de la firme est loin d’être à la hauteur dans les jeux et démos utilisant DirectX 9. Alors que quelques mois auparavant, NVIDIA vantait les capacités de sa puce allant au delà de DirectX 9, en pratique les performances des Pixel Shaders en calcul flottant sont très en retrait. L’humiliation est à son comble quand certains développeurs parviennent à modifier les démos de la GeForce FX pour les faire tourner sur la Radeon 9700 et que cette dernière obtient de bien meilleures performances que le fleuron de NVIDIA !

Pour la première fois depuis le NV1, NVIDIA a chuté de son piédestal et certaines fissures commencent à apparaître dans l’image de marque jusqu’ici parfaitement contrôlée par la firme. La communication est plus floue, avec moins de détails techniques sur le GPU, afin d’éviter les comparaisons directes, forcément défavorables, avec le GPU de son concurrent. NVIDIA emploie aussi certaines pratiques discutables dans ses drivers, remplaçant automatiquement les shaders des jeux par des versions optimisées, mais pas toujours exactement équivalentes. En parallèle les ingénieurs de la marque, bien conscients des problèmes techniques de leur premier GPU DirectX 9, travaillent d’arrache pieds pour fournir un nouveau GPU, afin de combler les lacunes du NV30.

Un des principaux problème du NV30 réside dans sa puissance de calcul en virgule flottante. Contrairement aux présentations marketing de NVIDIA, le NV30 est loin de marquer une rupture totale avec la génération précédente. On retrouve donc l’architecture de base du NV20/NV25 avec ses 4 unités de fragment shading, chacune équipée de deux unités de texture. En amont de cette unité de texture, on trouve une unité de calcul flottant, cette unité était relativement limitée sur NV20/25 et se contentait d’effectuer quelques opérations prédéfinies sur les coordonnées de textures.
Avec le NV30, NVIDIA a étendu les fonctionnalités de cette unité mais elle reste toujours responsable des opérations sur les coordonnées de texture. Le NV30 n’est par conséquent capable d’effectuer qu’une opération de calcul flottant par cycle OU une opération de texture par cycle, là où le R300 peut effectuer une opération de calcul flottant ET une opération de texture par cycle ! Sans compter que le R300 dispose de 8 pipelines contre seulement 4 pour le NV30. Toutefois, le NV30 dispose également de deux unités de calculs en précision fixe (FX12), les fameux register combiners, présents depuis le NV10. Ces unités lui permettent d’être compétitifs dans les jeux DirectX 8 mais pas dans les jeux DirectX 9 utilisant les opérations flottantes. Avec le NV35, NVIDIA corrige le tir, en remplaçant ces deux registers combiners par une deuxième unité de calcul en virgule flottante.
La guerre des GPU s’intensifie
Le NV30 ayant connu un retard important, le NV35 arrive à peine quelques mois plus tard et permet à NVIDIA de limiter un peu la casse dans la guerre qui l’oppose à ATI et à son architecture R3x0, mais les lacunes de l’architecture NV3x sont trop profondes, et ne peuvent être corrigées sans un remaniement plus important qui interviendra en 2004 avec le NV40. Hors de question de se laisser griller la politesse par ATI deux fois, de suite, le NV40 est donc le premier GPU à supporter le Shader Model 3.0 de la nouvelle révision de DirectX 9. Le R420 d’ATI n’arrivera que quelques semaines plus tard, et se contentera toujours du support du Shader Model 2.0.

Avec le NV40, NVIDIA revoit complètement sa copie. Fini l’usine à gaz du NV30/NV35 et ses unités très complexes, le NV40 mise sur la quantité et la flexibilité. Les nouvelles unités de fragment shading sont donc plus nombreuses : 16 au lieu de 4 et ces unités sont beaucoup plus flexibles vu qu’elles peuvent désormais effectuer soit une opération sur 4 composantes comme avant, soit une opération sur 3 composantes et sur un scalaire, soit deux opérations sur 2 composantes. Grâce à l’architecture moins complexe de ces unités, le travail d’optimisation s’en trouve simplifié et le GPU est plus susceptible de s’approcher de ses performances maximales.
ATI reste néanmoins un redoutable concurrent et mise également sur le parallélisme avec son R420 qui étend lui aussi le nombre d’unités de fragment shading à 16. Cette fois, la guerre des performances qui avait été remporté par KO par ATI à la génération précédente, est désormais beaucoup plus disputée.
En 2005, changement de nomenclature : point de NV50 au programme, c’est le G70 qui débarque. Cette fois, pas de révolution, NVIDIA reprend en grande partie l’architecture du NV40, étendant encore le nombre d’unités de vertex shading de 6 à 8 et le nombre d’unités de fragment shading de 16 à 24. Si le G70 n’a rien de bien marquant, cette architecture s‘avère redoutablement efficace, d’autant que c’est désormais au tour d’ATI de rencontrer des problèmes avec son R520 qui arrivera avec beaucoup de retard. Pendant un long moment, NVIDIA se retrouve donc de nouveau seul sur le marché du haut de gamme.
Début 2006, ATI se réveille avec un R580 qui vient rapidement faire oublier le R520. Et les performances sont au rendez-vous grâce à une puissance de calcul qui explose, avec pas moins de 48 unités de fragment shading contre 16 pour le R520. NVIDIA se doit de réagir et lance le successeur du G70, le G71 qui peut atteindre de plus hautes fréquences grace à un nouveau procédé de gravure. C’est un dérivé de cette architecture G71 qu’on retrouvera dans la PS3 sous le nom de code de RSX.

G80 : la révolution matérielle et logicielle

Mais la vraie révolution arrive à la fin de l’année 2006. Alors que depuis plusieurs années, ATI parle de sa future architecture unifiée, c’est à dire une architecture combinant les unités de vertex et de fragment shading au sein d’unités totalement génériques, NVIDIA fait profil bas. Et si ATI est fondamentalement le premier à présenter ce type d’architecture avec le Xenos, le GPU de la Xbox 360 sortie fin 2005, NVIDIA attend son heure et surprend tout le monde en dévoilant le G80 : une architecture non seulement totalement unifiée mais encore plus ambitieuse que la vision d’ATI.
Un simple coup d’oeil aux diagrammes d’architecture du G80 comparé à celui du G71 permet de bien saisir l’ampleur des changements :


Même en gardant à l’esprit que ces diagrammes sont des vues marketing, extrêmement simplifiées, ils traduisent une réalité indéniable : là où le G71 est avant tout un GPU, qui implémente en hardware le traditionnel pipeline graphique au sein d’unités spécialisées, le G80 est pour sa part un ensemble massivement parallèle d’unités de calculs en virgule flottante ce qui s’avère, entre autre, particulièrement bien adapté pour faire du rendu.
Cette différence de philosophie s’illustre bien au niveau des unités de calcul. Le G71, comme ses prédécesseurs avant lui, s’appuie sur des unités vectorielles Vec4 qui est le type de données le plus fréquemment manipulé dans le domaine graphique que ce soit avec les coordonnées (x, y, z, w) des sommets, ou les couleurs (r, g, b, a) des fragments. Mais les shaders devenant de plus en plus complexes, il devient fréquent de devoir utiliser d’autres types de données qu’elles soient scalaires ou de type Vec2 ou Vec3.

Dans ces cas là, une unité Vec4 n’est pas utilisée à sa pleine capacité. Pour limiter la perte de performances depuis le NV40, NVIDIA offre la possibilité de “découper” ses unités Vec4 en deux comme nous l’avons vu précédemment : soit Vec3+1, comme sur les GPU ATI depuis le R300, soit Vec2+2 ce qui est unique aux GPU NVIDIA. C’est ce qu’on appelle le co-issue. Mais cela implique des limitations, un shader entièrement scalaire n’utilisera les unités qu’à 50% au mieux, et surtout le mode co-issue implique obligatoirement l’absence de dépendances entre les deux instructions qui sont exécutées simultanément par l’unité vectorielle.
Avec le G80, NVIDIA veut une plus grande efficacité quel que soit le type de données et va pour cela introduire une architecture SIMT : Single Instruction Multiple Threads. La différence est plus philosophique que matérielle, en pratique qu’il s’agisse d’unités Vec4 ou SIMT, les unités sous jacentes sont des unités SIMD classiques, mais l’organisation des données est différente. Avec une unité vectorielle, la taille du vecteur est exposée là où la taille du vecteur d’une unité SIMT est arbitraire et totalement abstrait. Concrètement, supposons que nous voulons traiter 4 fragments avec une unité SIMT4 face à une unité SIMD Vec4 voici la différence de comportement :
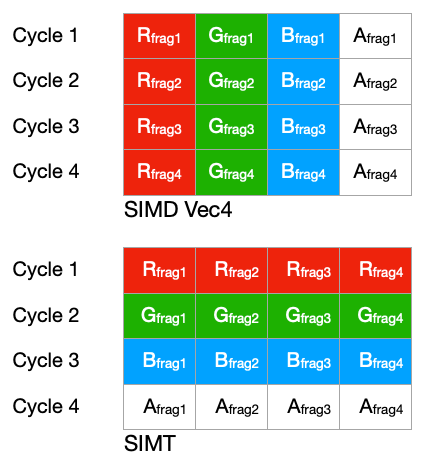
Dans ce cas là ça ne change effectivement rien, il s’agit juste d’un agencement différent des données. Maintenant supposons que nous souhaitons travailler uniquement sur la composante R des fragments, en effectuant le calcul suivant :
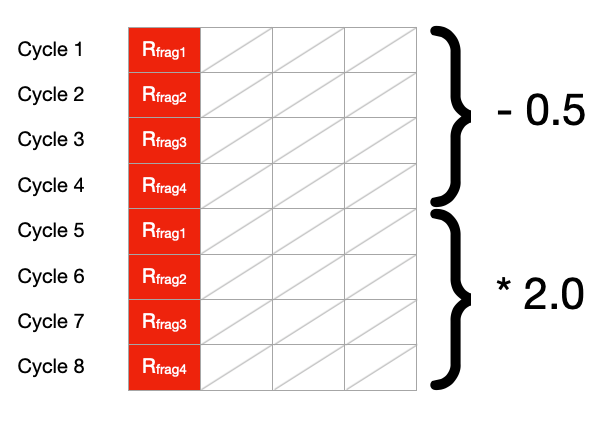
float x = (fragColor.r - 0.5)*2.0
Avec une unité SIMD, même co-issue, il est impossible d’effectuer ces instructions simultanément car elles sont dépendantes l’un de l’autre. On utilisera donc les unités à 25% de leur capacité maximale, pour traiter 4 fragments il faudra donc 8 cycles :
Avec des unités SIMT, le même calcul ne prend plus que deux cycles :

Outre ses unités de calcul améliorées, le G80 bénéficie de son architecture unifiée pour effectuer de l’équilibrage de charge. Si les moteurs de rendu modernes mettent davantage à contribution les fragments shaders, ils s’appuient généralement sur plusieurs passes de rendu dont certaines utilisent des fragments shaders très simples, comme lors des calculs d’ombre. Au cours de ces passes, les unités de fragment shading sont inutilisées et les unités de vertex shading sont saturées. A l’inverse lors des passes de post-traitement, les calculs géométriques sont très limités mais les calculs par fragments peuvent être très complexes. Grâce à son architecture unifiée, le G80 peut allouer ses unités de calcul dynamiquement en fonction de la charge et ainsi les exploiter au mieux.


La combinaison de toutes ces techniques, associées à des unités de calcul fonctionnant à une fréquence quasiment doublée par rapport au G71, permettent au G80 d’obtenir des performances impressionnantes avec un gain compris entre 70 et 80% comparé à son prédécesseur.
Mais NVIDIA a des ambitions plus importantes pour son nouveau GPU. Pour comprendre, la stratégie de la firme il faut revenir quelques années en arrière. Dès 2003 et l’arrivée de la GeForce FX, certains chercheurs ont vu l’opportunité, offerte par les nouveaux GPU, de bénéficier d’une puissance de calcul flottant largement supérieure à celle des processeurs les plus rapides de l’époque. C’est ce qu’on appelle le GPGPU pour General-Purpose Computing on Graphics Processing Units autrement dit l’utilisation d’un processeur graphique pour des calculs génériques.
Pourtant, en pratique, la puissance de calcul du NV30 n’est pas vraiment impressionnante comparée à celle d’un Pentium 4. Mais les performances en calcul flottant des GPU évoluent vite contrairement à celles des CPU.

Toutefois, exploiter cette puissance est compliquée. Le seul moyen de l’utiliser est par le biais des API graphiques, comme OpenGL 2.0 ou DirectX 9, qui ne sont pas particulièrement adaptées à ce type d’usage et qui demandent des connaissances très spécifiques de programmation graphique. Avant de pouvoir utiliser un quelconque shader, il faut notamment configurer tous les paramètres d’affichage qui n’ont aucun intérêt ici et peuvent paraître bien obscurs à des non spécialistes du domaine. De la même façon, avec une API comme OpenGL 2.0 ou DirectX 9, un shader ne peut être appliqué qu’à une primitive graphique, il faut donc initier un appel de rendu fictif avant de pouvoir effectuer des calculs. Parmi les autres limitations, on peut également citer des opérations de lecture/écriture mémoires très limitées, ainsi que l’absence de débugueur digne de ce nom.

Afin de permettre à des non spécialistes d’utiliser les GPU comme un coprocesseur de calcul, des chercheurs de l’université de Stanford vont proposer une nouvelle API : BrookGPU qui se charge d’effectuer une abstraction de l’API graphique sous jacente. Mais, si cette abstraction avait le mérite de simplifier la mise en place d’une application GPGPU, elle ne pouvait s’affranchir des limites évoquées plus haut. De plus, elle restait extrêmement dépendante des pilotes graphiques sous jacents. BrookGPU était donc loin d’offrir la robustesse nécessaire à des applications de qualité industrielle et resta l’apanage du monde de la recherche. Malgré tout, cette API avait ouvert la voie en montrant qu’il y avait une vraie demande pour ce type d’usages.
Le succès d’estime de BrookGPU, a suffit à capter l’attention de NVIDIA qui a vite compris le potentiel offert par le GPGPU et s’est adjoint les services d’une bonne partie de l’équipe derrière cette API. Dès le lancement de son G80, NVIDIA présente donc CUDA son API de GPGPU propriétaire. Contrairement aux efforts précédents, CUDA est une véritable API dédiée qui ne s’appuie pas sur le pilote graphique pour adresser le GPU, CUDA repose sur un pilote matériel distinct. Le code généré est donc plus robuste et beaucoup moins susceptible de subir les aléas des mises à jours fréquents des pilotes graphiques.

Avec CUDA, il est également inutile de contorsionner son problème pour l’exprimer d’une façon compatible avec une API graphique. NVIDIA s’appuie en effet sur le langage C standard, auquel la firme a ajouté quelques extensions afin de pouvoir exploiter pleinement l’architecture de son GPU. Et l’architecture du G80 a justement été conçue avec CUDA en tête. En effet, NVIDIA a pris le risque d’intégrer des unités uniquement exploitables dans le cadre du GPGPU. C’est le cas notamment de la Shared Memory, une zone mémoire de 16Ko présentes au sein de chaque multiprocesseur et permettant aux threads de communiquer sans passer par la mémoire externe qui est inaccessible dans les API graphiques. Dédier des ressources uniquement destinées à un marché encore inexistant, montre bien la détermination de NVIDIA.
On ne le sait pas encore mais en 2007 en introduisant CUDA, NVIDIA vient de réaliser un coup de maître. Son API s’impose comme un standard de fait qui lui permet de se faire une place de choix dans le monde du HPC (High Performance Computing). 13 ans plus tard, il est impossible de trouver un supercalculateur qui ne s’appuie pas sur des GPU.
La maturité
Le G80 renverse tout sur son passage à commencer par la concurrence. Premier GPU né de la fusion d’AMD et d’ATI, le R600 ou Radeon HD 2900 est une déception qui ne peut lutter avec le haut de gamme de NVIDIA. Mais comme bien souvent après l’apparition d’un produit aussi marquant, la suite est moins passionnante, le G80 ayant posé les grandes lignes de tous les futurs GPU de NVIDIA pour les années à venir. La firme de Santa Clara va donc longtemps s’appuyer sur l’architecture du G80, en introduisant d’abord un dérivé destiné avant tout à réduire les coûts : le G92 apparaît donc un an plus tard, fin 2007. Le véritable successeur du G80, le GT200 apparaît mi-2008 mais là encore il reprend en grande partie l’architecture du G80 en augmentant toutefois sensiblement le nombre d’unités de calculs.

Il faudra attendre l’architecture Fermi, apparue début 2010, pour voir NVIDIA proposer un remaniement un peu plus substantiel de son architecture. Avec le GF100, NVIDIA mise tout sur le GPGPU avec des performances double précision largement supérieures au GT200, une quantité beaucoup plus importante de Shared Memory, le support de l’instruction FMA en simple précision ou encore le support de la mémoire ECC. L’architecture du GF100 est très ambitieuse, mais les joueurs s’inquiètent de l’accent mis sur le GPGPU au détriment peut-être des performances graphiques.
Car dans le même temps AMD a avancé ses pions discrètement. Après le désastreux R600, AMD change de stratégie et abandonne le haut de gamme pour se concentrer sur le “sweet spot” : le rapport qualité prix idéal. La première architecture issue de cette stratégie est le RV670 un dérivé du R600, optimisé et bien moins coûteux qui, sans marquer spécialement les esprits, reste un GPU honorable.

Son successeur, le RV770 arrivé mi-2008 est en revanche une vraie bonne surprise : s’il est moins ambitieux que le GT200 de NVIDIA, il offre un rapport qualité prix imbattable et ses performances lui permettent même d’aller titiller le haut de gamme de la firme de Santa Clara. Mais c’est le RV870, ou Cypress, qui met tout le monde d’accord. Premier GPU DirectX 11 à débarquer fin 2009, le RV870 avec ses performances de premier plan met la pression sur NVIDIA alors que le GF100 est en retard. Lorsque Fermi arrive enfin début 2010, la compétition avec AMD s’avère rude. Non seulement le RV870 est largement compétitif, mais il est aussi sensiblement moins cher.
Début 2012, AMD est le premier à proposer sa nouvelle architecture GCN qui s’éloigne enfin drastiquement de celle apparue avec le R600 et reprend quelques idées de l’architecture NVIDIA. Et pour bien marquer le coup, AMD revient sur le segment haut de gamme avec sa Radeon HD7970. AMD en profite également pour intégrer son architecture GCN aux deux consoles de nouvelle génération : la PS4 et la Xbox One.
La réponse de NVIDIA ne se fera pas attendre avec son architecture Kepler. Conscient des problèmes de Fermi, NVIDIA a appris de ses erreurs et lance en premier lieu une déclinaison milieu de gamme le GK104, qui vise avant tout les joueurs, le GK110 version haut de gamme n’arrivant qu’un an plus tard, début 2013.


NVIDIA semble donc avoir adopté une cadence proche du fameux tick-tock d’Intel, alternant une révision majeure de son architecture (G80, Fermi), avec une déclinaison moins ambitieuse qui se contente d’optimiser l’architecture précédente (GT200, Kepler). En 2014 pour sa nouvelle révision majeure dénommée Maxwell, NVIDIA se retrouve face à un challenge inédit : avec le ralentissement de l’amélioration des procédés de gravure des fondeurs, NVIDIA doit proposer un vrai saut générationnel, tout en restant sur le même procédé 28nm de TSMC, déjà utilisé depuis deux ans et demi par Kepler.
Dans ces conditions, difficile de s’appuyer sur une augmentation massive du nombre de transistors. Avec 7 milliards de transistors et un die de 561mm², le GK110 est déjà à la limite. Par conséquent, NVIDIA va devoir revoir son architecture en profondeur afin d’augmenter son efficacité.

Et les ingénieurs réalisent un petit miracle. Le GM204, malgré ses 5.2 milliards de transistors et un die de 398mm² sensiblement inférieur à celui du GK110, offre un gain de performance digne des changements de génération habituels. Pour réaliser un pareil tour de force, NVIDIA s’est inspiré des puces mobiles. Celles-ci s’appuient sur une technique de rendu apparue aux tous débuts des cartes 3D sur PC avec les puces PowerVR : le Tile Based Rendering. Si cette technique n’a pas rencontré le succès sur PC, elle s’est imposée comme incontournable dans les GPU dédiées aux architectures mobiles.
Là où un GPU classique va traiter chaque triangle dans l’ordre dans lequel il arrive (immediate mode renderer), un tile renderer découpe l’image finale en tuiles d’une taille fixe (16x16, 32x32…) et accumule les informations de tous les triangles qui couvrent une tuile avant d’effectuer le rendu. Une fois qu’ils sont tous enregistrés, le tile renderer peut traiter la tuile dans son intégralité et stocker le résultat final dans une petite zone mémoire directement intégrée au processeur graphique.
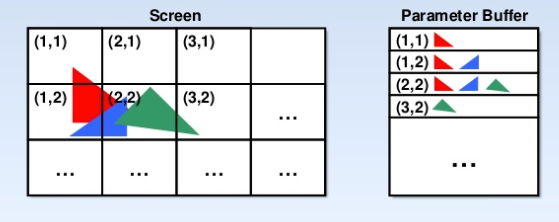
Cette technique offre l’avantage d’économiser énormément de bande passante vers la mémoire graphique et donc d’améliorer les performances. En effet au lieu d’effectuer de nombreuses transactions vers la mémoire externe pour chaque pixel, le GPU va écrire directement la tuile en mémoire en une seule transaction. Mais le gain de performance n’est pas le seul intérêt de cette approche, la bande passante vers la mémoire consomme beaucoup d’énergie, largement plus que ce que peut consommer une unité de calcul par exemple. Cette technique augmente donc l’efficacité énergétique du GPU, ce qui explique son succès dans les architectures mobiles.
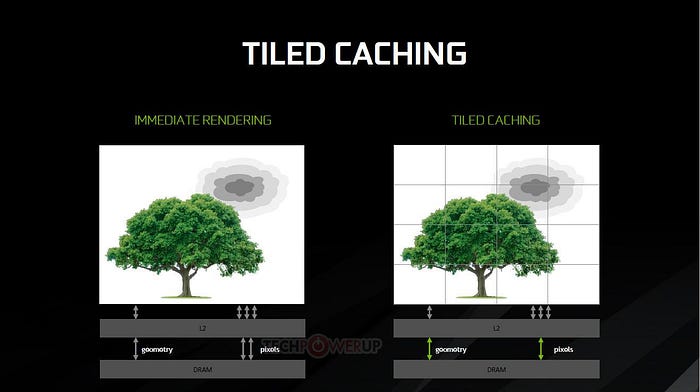
NVIDIA implémente une variation de cette technique baptisée Tiled Caching avec son architecture Maxwell. Plutôt que de s’appuyer sur une zone mémoire spécifique, les ingénieurs ont augmenté massivement la quantité de mémoire cache de niveau 2 du GPU afin de pouvoir y stocker les informations des tuiles. De 512Ko sur Kepler on passe ainsi à 2Mo sur Maxwell. Le Tiled Caching permet donc de consommer largement moins d’énergie tout en améliorant les performances et fait de Maxwell une référence en termes de performances-par-watt. Cette efficacité portera un coup fatal à AMD, dont l’architecture GCN avait déjà du mal à suivre sur ce point face à Kepler. Avec Maxwell, AMD se retrouve donc dans une position très inconfortable dont il mettra beaucoup de temps à sortir.

Pendant ce temps, NVIDIA continue sur sa lancée. En 2016, TSMC propose enfin un nouveau procédé de gravure : le 16nm. Grâce à celui-ci et à une optimisation de l’architecture, déjà excellente, de Maxwell, NVIDIA enfonce le clou avec son architecture Pascal. Montant à des fréquences beaucoup plus élevées que Maxwell, Pascal atteint un niveau de performances jamais vu et NVIDIA se succède donc à lui même sur le segment haut de gamme.
En 2018, c’est au tour de Turing de débarquer et encore une fois NVIDIA est en concurrence avec lui même. Contraint de s’appuyer une nouvelle fois sur un procédé 16nm, bien qu’un peu optimisé et renommé pour l’occasion 12nm, NVIDIA ne parvient pas à offrir un gain de performances similaire aux précédents changements de génération. Mais NVIDIA dispose de deux arguments pour vendre sa puce. Tout d’abord, l’accélération matérielle du Ray-Tracing qui, dans le domaine de l’infographie fait figure de Grall. Et ensuite l’ajout de Tensors Cores, des unités spécialisées dans les calculs d’apprentissage machine dont nous parlerons plus en détails dans la prochaine partie.

Voilà qui nous amène en cette fin d’année 2020. L’architecture Ampère de NVIDIA vient d’arriver mais, pour la première fois depuis longtemps, AMD semble être en mesure de riposter avec son architecture RDNA2 qui vient tout juste d’être dévoilée.


Nous venons de terminer ce tour d’horizon de 25 ans de processeurs graphiques. Au cours de cette rétrospective, vous avez pu constater la transformation de ce qui n’était au départ qu’un simple coprocesseur graphique, en un rouage essentiel du monde de l’informatique hautes performances.

Qu’elle semble loin l’époque où Tom Duff, un employé de Pixar se payait la tête de Jen Hsun Huang qui, dans son extravagance habituelle, avait osé dire il y a 20 ans que la GeForce 2 GTS était le premier pas vers un rendu digne de Pixar en temps réel. Si Tom Duff n’hésitait pas à qualifier dédaigneusement le GPU de NVIDIA de “jouet”, nul doute que son opinion a bien changé maintenant que les GPU et CUDA ont envahi les fermes de rendu de Pixar.
Grâce à des capacités de calcul parallèle qui ont augmenté à un rythme effréné et au développement de tout un écosystème dédié au calcul parallèle hautes performances, le GPU s’est imposé comme un composant essentiel de tout supercalculateur moderne. Dans ces conditions, il n’est pas surprenant qu’AMD ait racheté ATI il y a 15 ans et qu’intel ait tenté désespérément d’intégrer ce marché à plusieurs reprises. D’abord il y a plus de 20 ans avec son i740, puis une nouvelle fois il y a 10 ans avec son projet Larrabee, et enfin plus récemment avec son architecture Xe. Face à cette consolidation du marché, NVIDIA fait le chemin inverse en rachettant Arm pour 40 milliards de dollars.


Ainsi, le GPU s’est depuis longtemps affranchi du seul domaine graphique, ses nouvelles attributions sont variées. Parmi celles-ci nous pouvons citer la modélisation climatique, la biologie moléculaire, la modélisation financière ou encore les calculs d’apprentissage machine dont il sera question dans la prochaine partie de cet article.
